Prompt Contracts: Why Your AI Gives Perfect Answers to the Wrong Questions
You asked AI for help with your API strategy. You got a beautifully formatted tutorial about what APIs are. The response was flawless. It was also useless.
The AI didn't fail. You signed the wrong contract.
The $90,000 Lesson Hidden in Four Words
Watch what happens when we change one verb in prompts about APIs:
"Tell me about APIs"
Result: A comprehensive overview with restaurant metaphors. Perfect for onboarding. Worthless for your board deck.
"Define REST API architecture"
Result: Formal principles—statelessness, cacheability, uniform interface. What goes in your engineering handbook. Not what convinces your CEO.
"Compare REST and GraphQL"
Result: A decision matrix covering overfetching, caching, versioning. Helpful for choosing. Still no numbers for your business case.
"Evaluate REST vs GraphQL with metrics"
Result: GitHub reduced payloads by 90%. Facebook cut cellular data by 70%. Shopify saw 3-5x reduction in mobile checkout queries. Now you can make a $90,000 infrastructure decision.
None of these responses was wrong. Only one was right for your task.
The Contract You Don't Know You're Signing
Every prompt verb purchases a different deliverable:
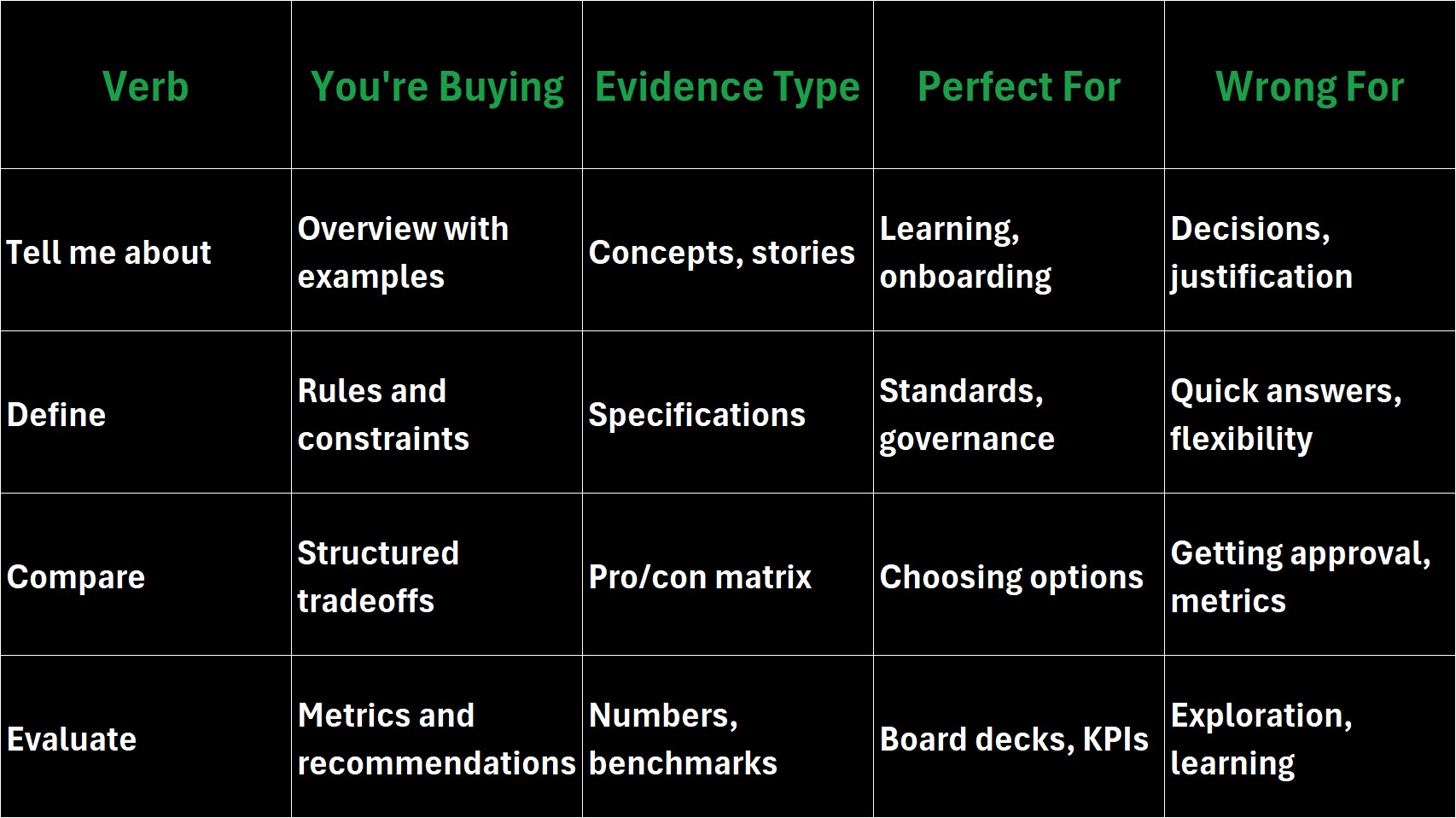
This isn't AI struggling with vague language. It's AI perfectly executing the contract you accidentally signed.
The Three-Step System That Changes Everything
Before you type any prompt, run this pattern:
Step 1: Name the job
Decision? Orientation? Standard-setting? One word is enough.
Step 2: Choose your contract verb
Match the verb to the job, not your curiosity.
Step 3: Specify the evidence
Metrics? Examples? Policies? Include audience and context.
Real Implementation: A Mobile Checkout Case Study
Your team needs to optimize checkout for spotty cellular networks. Here's the difference:
Wrong contract: "Tell me about GraphQL"
Right contract: "Evaluate REST vs GraphQL for mobile checkout on 3G networks"
Here's what the evaluation delivers:
REST Approach:
Requests: GET /user (120ms, 8KB) → GET /cart (120ms, 6KB) → GET /items (120ms, 8KB)
Total: 3 sequential requests, 360ms latency, 22KB payload
Caching: Strong at endpoint level, CDN-friendly
GraphQL Approach:
Requests: Single query for user.name, cart.id, items[price, quantity]
Total: 1 request, 120-160ms latency, 8-12KB payload
Caching: Requires resolver strategies or persisted queries
For bandwidth-constrained users, GraphQL saves 240ms and 10-14KB per checkout. At 10,000 daily checkouts, that's 20 hours of user wait time eliminated per month.
Copy-Ready Templates for Every Contract
Evaluation Template (for decisions with numbers)
Evaluate [Option A] vs [Option B] for [specific workflow], include:
- Number of requests and total round-trip time
- Average payload size per operation
- Latency on [3G/4G/fiber]
- Caching complexity and cache hit rates
- Implementation risk and timeline
- Recommendation for [specific audience]
Comparison Template (for option selection)
Compare [Option A] and [Option B] for [use case] across:
- [Dimension 1: e.g., overfetching]
- [Dimension 2: e.g., client complexity]
- [Dimension 3: e.g., operational cost]
Provide a decision matrix and one-paragraph summary for [stakeholder type]
Definition Template (for standards and governance)
Define [concept/architecture] for our [document type]. Include:
- Core principles and constraints
- Required patterns and anti-patterns
- Naming conventions and status codes
- Deprecation and versioning policy
Format for [audience: engineers/auditors/partners]
Overview Template (for education)
Tell me about [topic] with:
- Two practical examples from [industry/scale]
- Common misconceptions to avoid
- Glossary of essential terms
- Next steps for someone who wants to implement
Why This Breaks Most AI Initiatives
Developer scenario: Sprint planning tomorrow. You need to know if switching to GraphQL will hit your Q2 latency targets.
Ask "tell me about GraphQL" → Get a Wikipedia entry
Ask "evaluate GraphQL for our mobile app with P95 latency metrics" → Get the numbers that justify your sprint
Content/SEO scenario: You're targeting "REST vs GraphQL" searches.
Informational intent (60% of searches) needs "tell me about"
Commercial intent (30% of searches) needs "compare"
Transactional intent (10% of searches) needs "evaluate with metrics"
Publish the wrong contract for search intent → great content, zero conversions
Founder scenario: Board meeting in 2 hours.
"Tell me about our API options" → Nothing for your slides
"Evaluate our API strategy with cost and performance metrics" → The 90% efficiency gain that gets approval
Product Implications: Bake Contracts Into Your AI Features
Stop making users write prompts. Build the contracts into your UI:
Intent Detection: User clicks "Help with API decision" → System uses "evaluate" contract
Progressive Disclosure: Start with "tell me about" for exploration → Offer "evaluate" when user shows decision intent
Template Library: Pre-built contracts for common jobs in your domain
Prompt Rewriting: Detect vague prompts → Suggest specific contract upgrades
Slack could detect "How should we..." questions and offer: "Would you like an overview, comparison, or evaluation with metrics?"
The Competitive Edge No One's Talking About
While your competitors get comprehensive overviews, teams that understand prompt contracts get:
Metrics that justify technical decisions (not explanations of what metrics are)
Comparisons that accelerate choices (not definitions of the options)
Standards that prevent scope creep (not discussions about why standards matter)
Evaluations that close deals (not introductions to the concept)
This isn't about prompt engineering. It's about recognizing that perfect execution of the wrong contract is still failure.
The Takeaway That Changes Your AI ROI
Modern AI doesn't get confused by vague language—it honors vague contracts perfectly. When you ask to "tell me about," you get told about. When you ask to "evaluate with metrics," you get metrics. The precision is absolute. The results are exactly what you requested.
Your prompts are purchase orders. The AI will fulfill any contract flawlessly.
Stop ordering overviews when you need evaluations. Stop requesting definitions when you need comparisons. Name the job, choose the right contract, specify the evidence.
Sign the right contract. Get the right deliverable. Ship the right decision.
None of these contracts is wrong. Only one is right for your task.